La data au service de l’humain ou l’humain au service de la data ?


Lorsque l’on parle du Lean, on parle d’améliorer les performances de nos organisations. Mais encore faut-il connaitre nos problèmes et nos potentiels d’amélioration pour pouvoir nous améliorer.
Chez XL, c’est dans cet esprit que nous utilisons les données avec 4 objectifs principaux :
- Piloter l’activité et réagir au plus tôt en cas de dérives sur une ou plusieurs données observées régulièrement (voir notre dernière web-conférence dédiée à l’Animation à Intervalles Courts).
- Voir et comprendre les problèmes qui sont dans nos activités : Problématiques de délais (qualité de service), de qualité (Rendement qualité/ rebut) qui se traduisent par des pertes économiques (le coût, la productivité).
- Permettre de rendre factuel les échanges et le partage d’opinions. Dans un monde complexe, les solutions sont souvent ambiguës et il faut faire des arbitrages entre des enjeux différents. Les organisations « silotées » ont du mal à traiter ces problèmes transverses aux interfaces entre les services (voir explications un peu plus loin dans ce document).
- Estimer et valoriser les gains en fin de chantier et se rappeler d’où l’on vient. Et oui, on n’est jamais parfait et lorsque l’on pense Lean, on vise 60% du gain en 3 à 5 jours. N’oublions pas de se féliciter de nos petites victoires ! Ne pas se rappeler d’où l’on vient et de nos progrès dans un monde qui bouge vite, c’est beaucoup trop fréquent. C’est bien meilleur pour le moral de tous et nous donne confiance dans notre capacité à nous améliorer sur d’autres sujets !
Alors oui la donnée est importante, mais quelles données ? Comment les organiser et surtout comment donner du sens à ces données pour les équipes et permettre un engagement commun ? Les données ne manquent pas dans les organisations qui pourtant se plaignent de ne pas s’y retrouver. Faisons un petit détour par le monde du sport pour voir l’intérêt et les limites des approches centrées sur la data.
Cas du Sport : Des data qui permettent plus de performance
Prenons un sport d’endurance comme le cyclisme.
Nous connaissons depuis plus de 30 ans les cardiofréquencemètres qui mesurent notre fréquence cardiaque. Ils sont utilisés pour planifier des séances d’entrainement adaptées aux objectifs du moment des athlètes (travailler les filières aérobies et anaérobies par exemple pour travailler l’endurance ou l’explosivité). Avec ces plans d’entrainements, les athlètes sont arrivés à des performances supérieures tout en réduisant leur kilométrage annuel. Ils travaillent qualitativement sur les filières nécessaires et apprennent en fonction des résultats obtenus à mieux cibler leurs efforts.
Au début des années 2010, des équipes ont commencé à utiliser plusieurs capteurs supplémentaires pour analyser différentes situations et démontrer par exemple scientifiquement qu’il était parfois préférable de rester assis en montagne plutôt que de se relever de la selle pour accélérer (le rendement énergétique est meilleur et cela permet de s’économiser pour le final).
Les vélos et athlètes se sont enrichis :
- Capteurs intégrer dans les pédales pour mesurer la puissance en temps réel
- Capteur de fréquence de pédalage (l’objectif étant d’avoir une fréquence élevée pour soulager les muscles)
- GPS et altimètres
- …
Les compteurs ont évolué et indiquent les écarts par rapport aux objectifs (fréquence cardiaque trop haute, fréquence de pédalage trop basse ou bien encore trop de dépense d’énergie…) permettant de piloter en temps réel sa propre performance.
Les données se sont accumulées pour chaque coureur qui peut ainsi redéfinir en permanence ses objectifs atteignables en compétition et comment les travailler à l’entrainement. Les performances sont plus élevées mais au prix d’une complexité accrue. Il est maintenant acquis que les coureurs ne peuvent plus être à 100% de leur forme sur 1 saison et doivent mieux cibler leurs objectifs. Les compétences des entraîneurs se sont enrichies de nouvelles compétences (compréhension des données en lien avec les compétences biologiques qui ont progressé en parallèle : fonctionnements musculaire, cardiaque…). De nouveaux métiers sont apparus, spécialisés dans l’analyse des data pour aller plus loin dans la compréhension. La quantité de données est devenue tellement grande que des méthodes sont nécessaires pour mieux les analyser et répondre à nos questions : bienvenue dans l’ère du Big Data et de ses algorithmes.
Ainsi, les coureurs du tour de France ne perdent aujourd’hui quasiment plus de poids pendant les 3 semaines du Tour de France. Ils suivent tous les jours les dépenses énergétiques pour adapter leurs rations quotidiennes. Cela ne vous fait peut-être pas rêver, je comprends. On arrive là dans les limites humaines de cette démarche centrée sur l’amélioration de la performance par la data.
Plusieurs sportifs ou coachs dénoncent le « trop de data » qui fait parfois perdre le sens aux athlètes. Des athlètes continuent de courir à l’instinct et de débrancher les capteurs dans les moments clés pour pouvoir se concentrer sur leur sensation. Cela démontre qu’ils peuvent encore atteindre des performances que les capteurs ne prédisaient pas. Et surtout, l’excès de data peut apporter une saturation d’informations pour le coureur et des effets de « BurnOut » qui apparaissent (perte de sens et d’envie) se traduisant par des pertes de performances inexpliquées par la science.
La démarche d’amélioration de la performance doit donc prendre en compte les facteurs humains et c’est bien l’intérêt de travailler en complément avec des coachs sportifs spécialisés dans le mental.
Mais revenons-en à nos entreprises. La situation n’est pas si éloignée que cela.
Des conflits de fonctions et d’objectifs
Lorsque l’on regarde une entreprise traditionnelle, les fonctions (services) ont des objectifs qui peuvent être antagonistes à d’autres :
- Ainsi, le commerce aura peut-être tendance à vendre avec des délais plus courts que la production le souhaite pour pouvoir atteindre son chiffre d’affaires.
- La production voudra lisser au maximum pour pouvoir optimiser ses ressources (les fameux TRS (Taux de Rendement Synthétique) des machines par exemple en agrandissant les tailles de lot pour moins changer de série).
- Le marketing lancera une campagne de promotion sans consulter l’état des stocks de la Supply Chain, impactant les ruptures du service mais en améliorant sa visibilité pour les client.
Dans ce cas, nous observerons beaucoup d’indicateurs calculés localement pour démontrer la performance d’un service mais cette performance aura des conséquences peu maîtrisées sur les autres services et surtout sur la performance globale.
Le schéma ci-dessous représente une approche traditionnelle :
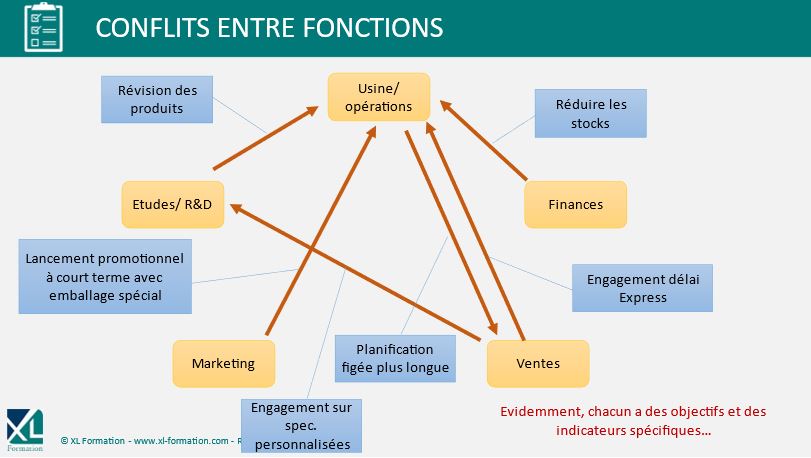
D’un point de vue data, nous observons beaucoup de fichiers isolés calculés par différentes personnes avec des hypothèses de constructions différentes, voir des erreurs qui conduisent à de réelles difficultés d’interprétation.
On arrive en quelque sorte dans la même situation que l’athlète qui est submergé par les data et les différentes injonctions parfois contradictoires (i.e. consignes pour l’athlète : Accélère mais pas trop longtemps, change de vitesse mais en baissant ton rythme cardiaque...).
En résumé les indicateurs sont donc locaux, calculés à partir de données pas forcément fiables et non représentatives de la performance globale de l’entreprise.
L’organisation de la donnée
Les organisations qui réussissent à structurer leurs univers de données, maitrise le lien entre la donnée et la situation physique opérationnelle. D’un point de vue Lean, la data doit être l’image la plus fidèle possible au terrain (Gemba). Et par définition, elle ne sera jamais la réalité complète qui est visible sur le terrain mais une image que l’on construit et fiabilise. Pour permettre un bon pilotage, elle devra être la plus visuelle possible, simple dans sa compréhension pour la personne qui l’utilise.
Deux éléments clés sont à noter :
- Les métiers s’approprient leur propre data et sont de plus en plus autonomes pour créer et adapter leurs propres outils digitaux qui mettent en forme les données.
- Il existe une proximité entre les métiers et les équipes Système d’Information qui permet un alignement entre les métiers, les utilisateurs et les développeurs ou architectes qui font évoluer les outils numériques (systèmes pour capter les données, les structurer et rendre possible leur interprétation).
De nouveaux métiers apparaissent alors dans l’organisation qui va alors se mettre à apprendre avec les données sans perdre pied avec le terrain :
- Les « datamaster » qui sont dans les organisations métiers (Supply Chain, Production, Qualité, Commerce…) et qui seront en quelques sorte les garants de la qualité et de l’interprétation de la data.
- Viendront alors s’ajouter des « Data Analyst», « Data Miner », « Business Intelligence Manager », Ingénieur Big Data.
Le flux pour mettre tout le monde d’accord
Alors comment y aller et s’y retrouver ?
Je vous propose de visionner le replay de la web-conférence dédiée à la Data Driven Factory mais sans trahir de secrets il est possible que l’on se centre sur les flux pour mettre en cohérence toutes ces données. Le reste suivra et les organisations trouveront un sens et des objectifs communs !
Nous parlerons BI (Business Intelligence), Lean 6 Sigma, Big Data pour voir comment tous ces outils peuvent nous aider, mais ils ne feront pas tout …








